Data scraping
Cineb.net scraping
The data scraped in this section are from the website cineb.net, from which I created a data set of movies and TV series.
As shown below, I have created an excel file with contents of said data in it.
Python code
from bs4 import BeautifulSoup
import requests, openpyxl
excel = openpyxl.Workbook()
print(excel.sheetnames)
sheet = excel.active
sheet.title = 'Top Rated Movies on CSFD.cz'
print(excel.sheetnames)
sheet.append(['Section', 'Media Type', 'Media Title', 'Year of Release', 'Length', 'Quality', 'Season', 'Episode' ])
try:
source = requests.get('https://cineb.net/')
source.raise_for_status
soup = BeautifulSoup(source.text, 'html.parser')
# first we want the movies in the featured
movies = soup.find('ul', class_="film-list-ul").find_all('li')
section = 'Featured'
mediatype = 'Movie'
episode = ''
season = ''
print('Section: ' + section)
for movie in movies:
name = movie.find('h3', class_="film-name").a.text
mytext = movie.find('div', class_="fd-infor").text
mysplit = mytext.split('\n')
quality = mysplit[1]
year = mysplit[2]
length = mysplit[4]
print('Movie: ' + name + "[" + quality + "] " + year + ' ' + length)
sheet.append([section, mediatype, name, year, length, quality, season, episode])
moviesCount = len(movies)
print(f'Featured movies: {moviesCount}')
# now we want the movies in the trending section
movies = soup.find(id="trending-movies").find_all('div', class_="flw-item")
section = 'Trending'
mediatype = 'Movie'
print('Section: ' + section)
for movie in movies:
name = movie.find('h3', class_="film-name").a.text
mytext = movie.find('div', class_="fd-infor").text
mysplit = mytext.split('\n')
quality = mysplit[1]
year = mysplit[2]
length = mysplit[4]
print('Movie: ' + name + "[" + quality + "] " + year + ' ' + length)
sheet.append([section, mediatype, name, year, length, quality, season, episode])
moviesCount = len(movies)
print(f'Trending movies: {moviesCount}')
# now we want the series in the trending section
movies = soup.find(id="trending-tv").find_all('div', class_="flw-item")
section = 'Trending'
mediatype = 'Series'
print('Section: ' + section)
year = ''
length = ''
for movie in movies:
name = movie.find('h3', class_="film-name").a.text
mytext = movie.find('div', class_="fd-infor").text
mysplit = mytext.split('\n')
quality = mysplit[1]
season = mysplit[2]
episode = mysplit[4]
print('Series: ' + name + "[" + quality + "] " + season + ' ' + episode)
sheet.append([section, mediatype, name, year, length, quality, season, episode])
moviesCount = len(movies)
print(f'Trending series: {moviesCount}')
except Exception as e:
print(e)
excel.save('Cineb Movies.xlsx')
Excel file
This is the contents of the Excel file with the scraped data:
Timejobs.com scraping
In this section we are looking at scraped data from timejobs.com
In this code, we are looking for jobs which require python skills and also the ability to exclude skills in which the user might not be proficient in. I have also set a timer in which, if there's case of new job posting python in them, it refreshes every 10 minutes and includes said jobs.
Python code
# in this code, I am trying to find job application with the serach of 'python'
from bs4 import BeautifulSoup
import requests
import time
# here I am trying to find skills that I am not familiar with so that i can rule them out
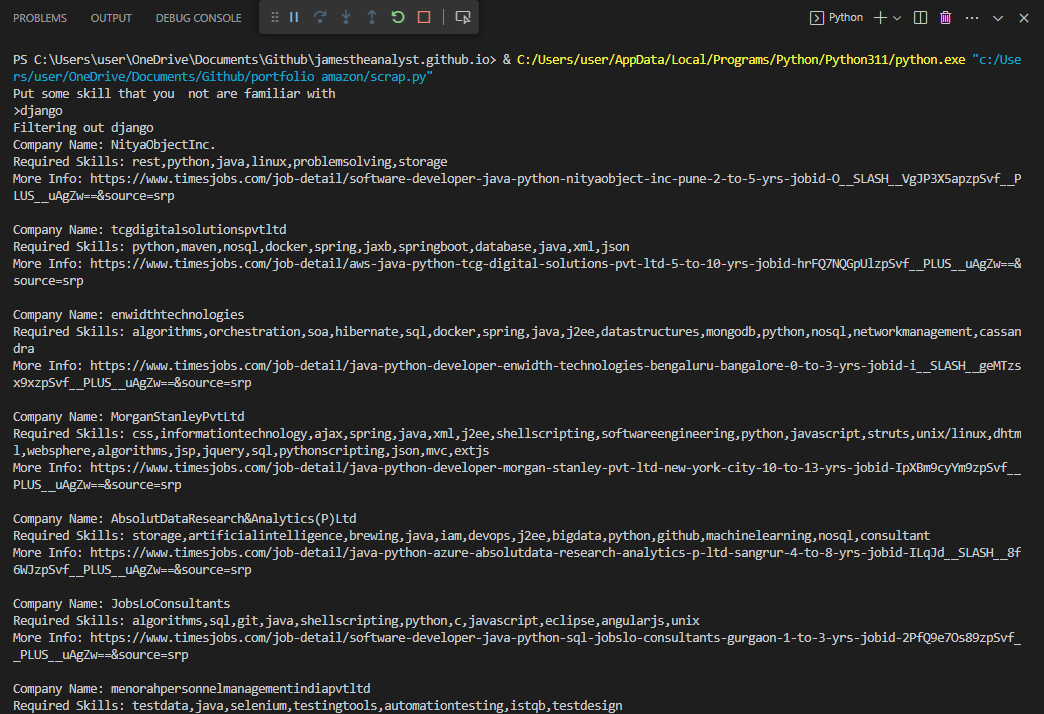
print('Put some skill that you not are familiar with')
unfamliar_skill = input('>')
print(f'Filtering out {unfamliar_skill}')
# In this segment, I am looking for jobs on this website
def find_jobs():
html_text = requests.get('https://www.timesjobs.com/candidate/job-search.html?searchType=personalizedSearch&from=submit&txtKeywords=Java+%2C+Python&txtLocation=').text
soup = BeautifulSoup(html_text, 'lxml')
jobs = soup.find_all('li', class_ = "clearfix job-bx wht-shd-bx")
for job in jobs:
posted_date = job.find('span', class_ = 'sim-posted').span.text
# in this portion of the code, I am trying to find job within a few days and not everything so the files i get back aren't too huge
if 'few' in posted_date:
company_name = job.find('h3', class_ = 'joblist-comp-name').text.replace(' ','')
skills = job.find('span', class_ = 'srp-skills').text.replace(' ','')
more_info = job.header.h2.a['href']
# And here again I am trying to rule out skills I dont know from the job search
if unfamliar_skill not in skills:
posted_date = job.find('span', class_ = 'sim-posted').span.text
print(f"Company Name: {company_name.strip()}")
print(f"Required Skills: {skills.strip()}")
print(f"More Info: {more_info}")
print('')
# the time i want this program running
if __name__ == '__main__':
while True:
find_jobs()
time_wait = 10
print(f'waiting {time_wait} minutes...')
time.sleep(time_wait * 60)
Results of running the code: